[둘째마당_본격실습! 데이터 갖고 놀기] 07 데이터 정제 - 빠진 데이터, 이상한 데이터 제거하기
현장에서 만들어진 실제 데이터는 오류를 포함하고 있기 때문에 분석하기 전에 수정부터 해야 함. 이 장에서는 데이터의 오류를 찾아 정제하는 방법을 익힘.
07-1 빠진 데이터를 찾아라! - 결측치 정제하기
결측치(missing value)는 누락된 값, 비어 있는 값을 의미함. 현장에서 만들어진 실제 데이터는 수집 과정에서 발생한 오류 때문에 결측치가 포함되어 있을 때가 많음. 결측치가 있으면 함수가 적용되지 않거나 분석 결과가 왜곡되는 문제가 발생함. 앞에서 사용한 예제 데이터들은 결측치가 없기 때문에 바로 분석했지만 실제 데이터를 분석할 때는 결측치가 있는지 확인해 제거하는 정제 과정을 거친 다음 분석해야 함.
[Do it! 실습] 결측치 찾기
결측치를 제거하는 방법을 알아보겠음. 먼저 결측치가 포함된 데이터 프레임을 만들어 출력하겠음.
결측치 만들기
결측치를 만들려면 Numpy 패키지의 np.nan을 입력하면 됨. 파이썬에서는 결측치를 NaN으로 표시함. 다음 코드의 출력 결과에서 sex의 세 번째 행과 score의 다섯 번째 행에 NaN으로 표시된 값이 결측치를 의미함.
import pandas as pd
import numpy as np
df = pd.DataFrame({'sex' : ['M', 'F', np.nan, 'M', 'F'],
'score': [5, 4, 3, 4, np.nan]})
df
NaN이 있는 상태로 연산하면 출력 결과도 NaN이 됨.
df['score'] + 1
결측치 확인하기
pd.isna()를 이용하면 데이터에 결측치가 들어 있는지 알 수 있음. pd.isna()에 df를 입력하면 결측치는 True, 결측치가 아닌 값은 False로 표시해 데이터를 출력함. 출력 결과를 보면 sex의 3행과 score의 5행이 결측치라는 것을 알 수 있음.
df.isna() # 결측치 확인
pd.isna()에 sum()을 적용하면 데이터에 결측치가 총 몇 개 있는지 출력함. 출력 결과를 보면 sex와 score에 결측치가 각각 1개씩 있다는 것을 알 수 있음.
df.isna().sum() # 결측치 빈도 확인
[Do it! 실습] 결측치 제거하기
결측치가 있는 행 제거하기
df.dropna()를 이용하면 결측치가 있는 행을 제거할 수 있음. subset에 []를 이용해 변수명을 입력하면 됨. 다음 코드를 실행하면 score가 결측치가 아닌 행만 출력됨.
df.dropna(subset = ['score']) # score 결측치 제거
이렇게 추출한 데이터를 변수에 할당하면 결측치가 없는 데이터가 됨. 결측치가 제거됐으니 연산하면 NaN없이 결과가 출력됨.
df_nomiss = df.dropna(subset = ['score']) # score 결측치 제거된 데이터 만들기
df_nomiss['score'] + 1 # score로 연산
여러 변수에 결측치가 없는 데이터 추출하기
앞에서는 score만 결측치가 없는 행을 추출했기 때문에 sex는 여전히 결측치를 포함하고 있음. df.dropna()의 subset에 변수를 나열하면 여러 변수에 결측치가 없는 행을 추출할 수 있음. 다음 코드의 출력 결과를 보면 score와 sex 모두 결측치가 없음.
df_nomiss = df.dropna(subset = ['score', 'sex']) # score, sex 결측치 제거
df_nomiss
결측치가 하나라도 있으면 제거하기
앞에서는 df.dropna()에 변수를 지정해 결측치가 있는 행을 제거하도록 코드를 구성했음. df.dropna()에 아무 변수도 지정하지 않으면 모든 변수에 결측치가 없는 행만 남김.
df_nomiss2 = df.dropna() # 모든 변수에 결측치가 없는 데이터 추출
df_nomiss2
이 방법은 결측치가 하나라도 있으면 모두 제거하므로 간편하지만, 분석에 필요한 행까지 손실된다는 단점이 있음. 예를 들어 성별, 소득, 지역 3가지 변수로 구성된 데이터로 분석하는 상황을 가정해 볼 때, 분석 목적이 성별에 따른 소득 차이를 알아보는 것이면 성별, 소득의 두 변수에서만 결측치가 있는 행을 제거하면 됨. 지역은 결측치더라도 분석하는데 문제가 없음. 그런데 이 방법을 사용하면 성별, 소득이 결측치가 아니어도 지역이 결측치인 행이 제거됨. 의도하지 않게 분석에 사용할 수 있는 데이터까지 제거되는 것임. 따라서 분석에 사용할 변수를 직접 지정해 결측치를 제거하는 방법을 권장함.
{알아 두면 좋아요} 결측치 제거하지 않고 분석하기
pd.mean(), pd.sum()과 같은 수치 연산 함수는 결측치가 있으면 자동으로 제거하고 연산하는 기능이 있음. groupby()와 agg()를 이용해 집단별 요약 통계량을 구할 때도 결측치를 제거하고 연산함.
df['score'].mean()
# output: 4.0df['score'].sum()
# output: 16.0df.groupby('sex').agg(mean_score = ('score', 'mean'),
sum_score = ('score', 'sum'))
자동으로 결측치를 제거하는 기능은 편리한 측면이 있지만, 결측치가 있는지 모른 채로 데이터를 다루게 된다는 위험이 있음. 데이터의 특징을 잘 이해하고 분석하기 위해 결측치가 있는지 직접 확인하고 df.dropna()를 이용해 명시적으로 제거하는 방법을 권함.
[Do it! 실습] 결측치 대체하기
데이터가 크고 결측치가 얼마 없을 때는 결측치를 제거하고 분석하더라도 무리가 없음. 하지만 데이터가 작고 결측치가 많을 때는 결측치를 제거하면 너무 많은 데이터가 손실되엉 분석 결과가 왜곡되는 문제가 생김.
결측치를 제거하는 대신 다른 값을 채워 넣는 방법도 있는데, 이를 결측치 대체법(imputation)이라고 함. 결측치를 다른 값으로 대체하면 데이터가 손실되어 분석 결과가 왜곡되는 문제를 보완할 수 있음.
결측치를 대체하는 방법에는 평균값이나 최빈값 같은 대푯값을 구해 모든 결측치를 하나의 값으로 일괄 대체하는 방법과 통계 분석 기법으로 결측치의 예측값을 추정해 대체하는 방법이 있음. 여기서는 평균값을 구해 일괄 대체하는 방법을 알아보겠음.
평균값으로 결측치 대체하기
먼저 exam.csv파일을 불러와 일부 값을 결측치로 바꾸겠음. 다음 코드는 2, 7, 14행의 math를 NaN으로 바꾸는 기능을 함. 출력 결과를 보면 2, 7, 14행의 math가 NaN으로 바뀐 것을 확인할 수 있음.
exam = pd.read_csv('exam.csv') # 데이터 불러오기
exam.loc[[2, 7, 14], ['math']] = np.nan # 2, 7, 14행의 math에 NaN 할당
exam
tip) df.loc[]는 데이터 위치를 지칭하는 역할을 함. [,]에서 쉼표 왼쪽은 행 위치, 쉼표 오른쪽은 열 위치를 의미함. 앞의 코드는 이 위치에 np.nan을 할당함. df.loc[]는 16-2절에서 자세히 다룸.
앞에서 만든 exam 데이터에서 2, 7, 14행의 math는 결측치임. 이 값들을 평균값으로 대체하겠음. 먼저 math의 평균값을 구하겠음.
exam['math'].mean()
# output: 55.23529411764706
평균값 55를 구했으니 math의 NaN을 55로 대체하겠음. df.fillna()를 이용하면 결측치를 다른 값으로 대체할 수 있음. 괄호 안에 결측치를 대체할 값을 입력하면 됨. 다음 코드를 실행하면 math의 결측치가 55로 바뀜. 출력 결과를 보면 2, 7, 14행의 math가 55로 수정된 것을 확인할 수 있음. 결측치 빈도를 확인하면 0이 출력됨.
exam['math'] = exam['math'].fillna(55) # math가 NaN이면 55로 대체
exam
exam['math'].isna().sum() # 결측치 빈도 확인
# output: 0{혼자서 해보기} 결측치가 들어 있는 mpg 데이터를 이용해 분석 문제를 해결해 보세요.
mpg 데이터 원본에는 결측치가 없음. 우선 mpg 데이터를 불러와 일부러 몇 개의 값을 결측치로 만들겠음. 다음 코드를 실행하면 다섯 행의 hwy 변수에 NaN을 할당함.
# mpg 데이터 불러오기
mpg = pd.read_csv('mpg.csv')
# NaN 할당하기
mpg.loc[[64, 123, 130, 152, 211], "hwy"] = np.nan
Q1. drv(구동 방식)별로 hwy(고속도로 연비) 평균이 어떻게 다른지 알아보려고 함. 분석을 하지 전에 우선 두 변수에 결측치가 있는지 확인해야 함. drv 변수와 hwy 변수에 결측치가 몇 개 있는지 알아보기.
mpg[['drv', 'hwy']].isna().sum()
Q2. df.dropna()를 이용해 hwy 변수의 결측치를 제거하고, 어떤 구동 방식의 hwy 평균이 높은지 알아보기. pandas 구문으로 만들어야 함.
mpg['hwy'] = mpg['hwy'].dropna()
mpg.groupby('drv') \
.agg(mean_hwy = ('hwy', 'mean')) \
.sort_values('mean_hwy', ascending = False)
07-2 이상한 데이터를 찾아라! - 이상치 정제하기
정상 범위에서 크게 벗어난 값을 이상치(anomaly)라고 함. 데이터 수집 과정에서 오류가 발생할 수 있기 때문에 현장에서 만들어진 실제 데이터에는 대부분 이상치가 들어 있음. 오류는 아니지만 매우 드물게 발생하는 극단적인 값이 데이터에 들어 있기도 함. 이상치가 들어 있으면 분석 결과가 왜곡되므로 분석에 앞서 이상치를 제거하는 작업을 해야 함.
[Do it! 실습] 이상치 제거하기 – 존재할 수 없는 값
논리적으로 존재할 수 없는 값이 데이터에 들어 있을 때가 있음. 예를 들어, 남자는 1, 여자는 2로 되어 있는 성별 변수에 3이라는 값이 들어 있는 경우임. 이는 분명한 오류이므로 결측치로 변환한 다음 제거하고 분석하면 됨.
이상치를 제거하는 방법을 알아보겠음. 먼저 이상치가 들어 있는 데이터를 만들겠음. 다음 코드로 만든 데이터는 1과 2 둘 중 하나로 분류되는 sex 변수와 1~5점으로 된 score 변수로 구성됨. 3행의 sex 변수에 이상치 3이 들어있고, 5행의 score 변수에 이상치 6이 들어 있음.
df = pd.DataFrame({'sex' : [1, 2, 1, 3, 2, 1],
'score': [4, 5, 3, 4, 2, 6]})
df

이상치 확인하기
데이터에 이상치가 들어 있는지 확인하려면 df.value_counts()를 이용해 빈도표를 만들면 됨. 다음 코드를 실행하면 sex에 존재할 수 없는 값 3이 하나 있고, score에 존재할 수 없는 값 6이 하나 있다는 것을 알 수 있음.
df['sex'].value_counts().sort_index()
df['score'].value_counts().sort_index()
tip) df.value_counts()에 sort_index()를 적용하면 빈도 기준으로 내림차순 정렬되지 않고 변수의 값 순서로 정렬함.
결측 처리하기
변수에 이상치가 들어 있다는 것을 확인했으니 이상치를 결측치로 바꾸겠음. np.where()을 이용해 이상치일 경우 NaN을 부여하면 됨. sex가 3이면 NaN을 부여하고, 3이 아니면 원래 가지고 있던 값을 부여하겠음. 출력 결과를 보면 3행의 sex 값이 NaN으로 바뀌었음.
# sex가 3이면 NaN 부여하기
df['sex'] = np.where(df['sex'] == 3, np.nan, df['sex'])
df
score 변수의 이상치도 결측치로 바꾸겠음. score는 1~5점을 지닐 수 있는 값이므로 5보다 크면 NaN을 부여하면 됨. 출력 결과를 보면 5행의 score 값이 NaN으로 바뀌었음.
# score가 5보다 크면 NaN 부여하기
df['score'] = np.where(df['score'] > 5, np.nan, df['score'])
df
sex, score 변수 모두 이상치를 결측치로 변환했으니 결측치를 제거하고 분석하면 됨. df.dropna()를 이용해 결측치를 제거한 다음 성별에 따른 score 평균을 구하겠음.
df.dropna(subset = ['sex', 'score']) \
.groupby('sex') \
.agg(mean_score = ('score', 'mean'))
{알아 두면 좋아요} np.where()는 문자와 NaN을 함께 반환할 수 없습니다.
np.where()는 반환하는 값 중에 문자가 있으면 np.nan을 지정하더라도 결측치 NaN이 아니라 문자 'nan'을 반환하므로 주의해야 함. 다음 코드의 출력 결과를 보면 조건에 맞지 않을 때 np.nan을 부여했는데도 출력값은 문자 'nan'임. df.isna()로 결측치가 있는지 확인해보면 모든 값이 False임.
df = pd.DataFrame({'x1':[1, 1, 2, 2]})
df['x2'] = np.where(df['x1'] == 1, 'a', np.nan) # 조건에 맞으면 문자 부여df
df.isna()
다음 절차를 따르면 변수를 문자와 NaN으로 함께 구성할 수 있음.
1. np.where()을 이용해 결측치로 만들 값에 문자를 부여함.
# 결측치를 만들 값에 문자 부여
df['x2'] = np.where(df['x1'] == 1, 'a', 'etc')# 'etc'를 NaN으로 바꾸기
df['x2'] = df['x2'].replace('etc', np.nan)
df
2. df.replace()를 이용해 결측치로 만들 문자를 np.nan으로 바꿈. df.replace()는 입력한 값을 다른 값으로 바꾸는 기능을 함.
df.isna()
[Do it! 실습] 이상치 제거하기 – 극단적인 값
논리적으로 존재할 수 있지만 극단적으로 크거나 작은 값을 극단치(outlier)라고 함. 예를 들어 몸무게 변수에 200kg 이상의 값이 있다면, 존재할 가능성은 있지만 매우 드문 경우이므로 극단치라고 볼 수 있음. 데이터에 극단치가 있으면 분석 결과가 왜곡될 수 있으므로 분석하기 전에 제거해야 함.
극단치를 제거하려면 먼저 어디까지를 정상 범위로 볼 것인지 정해야 함. 가장 쉬운 방법은 논리적으로 판단해 정하는 것임. 예를 들어 성인 몸무게가 40~150kg을 벗어나는 경우는 매우 드물다고 판단하고, 이 범위를 벗어나면 극단치로 간주하는 것임.
두 번째 방법은 통계적인 기준을 이용하는 것임. 예를 들어 상하위 0.3% 또는 ±3 표준편차에 해당할 만큼 극단적으로 크거나 작으면 극단치로 간주하는 것임.
상자 그림으로 극단치 기준 정하기
상자 그림은 중심에서 멀리 떨어진 값을 점으로 표현하는데, 이를 이용해 극단치의 기준을 정할 수 있음. 상자 그림을 이용해 극단치 기준을 구하는 방법을 알아보겠음.
1. 상자 그림 살펴보기
mpg 데이터의 hwy 변수로 상자 그림을 만들어 보겠음. seaborn 패키지의 boxplot()을 이용하면 됨.
tip) seaborn 패키지를 이용해 그래프를 만드는 방법은 8장에서 자세히 다룸.
mpg = pd.read_csv('mpg.csv')
import seaborn as sns
sns.boxplot(data = mpg, y = 'hwy')
상자 그림은 값을 크기순으로 나열해 4등분 했을 때 위치하는 값인 ‘사분위수’를 이용해 만듦. 다음은 상자 그림의 요소가 나타내는 값임.
| 상자 그림 | 값 | 설명 |
| 상자 아래 세로선 | 아랫수염 | 하위 0~25% 내에 해당하는 값 |
| 상자 밑면 | 1사분위수(Q1) | 하위 25% 위치 값 |
| 상내 내 굵은 선 | 2사분위수(Q2) | 하위 50% 위치 값(중앙값) |
| 상자 윗면 | 3사분위수(Q3) | 하위 75% 위치 값 |
| 상자 위 세로선 | 윗수염 | 하위 75~100% 내에 해당하는 값 |
| 상자 밖 가로선 | 극단치 경계 | Q1, Q3 밖 1.5 IQR 내 최댓값 |
| 상자 밖 점 표식 | 극단치 | Q1, Q3 밖 1.5 IQR을 벗어난 값 |
tip) ‘IQR(사분위 범위)’는 1사분위수와 3사분위수의 거리를 뜻하고, ‘1.5 IQR’은 IQR의 1.5배를 뜻함.
앞에서 출력한 상자 그림을 보면 hwy 값을 크기순으로 나열했을 때 하위 25% 지점에 18, 중앙에 24, 75% 지점에 27이 위치한다는 것을 알 수 있음. 직사각형 밖에 있는 아래, 위 가로선을 보면 12~37을 벗어난 값이 극단치로 분류된다는 것을 알 수 있음. 가로선 밖에 표현된 점 표식은 극단치를 의미함.
2. 극단치 기준값 구하기
(1) 1사분위수, 3사분위수 구하기
df.quantile()을 이용하면 분위수(quantile)를 구할 수 있음. 하위 25%에 해당하는 1사분위수와 75%에 해당하는 3사분위수를 구하겠음.
pct25 = mpg['hwy'].quantile(.25)
pct25
# output: 18.0pct75 = mpg['hwy'].quantile(.75)
pct75
# output: 27.0
(2) IQR 구하기
앞에서 구한 pct25와 pct75를 이용해 1사분위수와 3사분위수의 거리를 나타낸 IQR(inter quartile range, 사분위 범위)를 구함.
iqr = pct75 - pct25
iqr
# output: 9.0
(3) 하한, 상한 구하기
극단치의 경계가 되는 하한과 상한을 구함.
- 하한: 1사분위수보다 ‘IQR의 1.5배’만큼 더 작은 값
- 상한: 3사분위수보다 ‘IQR의 1.5배’만큼 더 큰 값
다음 코드의 출력 결과를 보면 hwy가 4.5보다 작거나 40.5보다 크면 상자 그림 기준으로 극단치라는 것을 알 수 있음.
pct25 - 1.5 * iqr # 하한
# output: 4.5pct75 + 1.5 * iqr # 상한
# output: 40.5
3. 극단치를 결측 처리하기
상자 그림의 극단치 기준값을 구했으니 np.where()를 이용해 기준값을 벗어나면 결측 처리하겠음. np.where()에 여러 조건을 입력할 때는 각 조건을 괄호에 감싸야 하니 주의해야 함.
# 4.5 ~ 40.5 벗어나면 NaN 부여
mpg['hwy'] = np.where((mpg['hwy'] < 4.5) | (mpg['hwy'] > 40.5),
np.nan, mpg['hwy'])
# 결측치 빈도 확인
mpg['hwy'].isna().sum()
# output: 3
4. 결측치 제거하고 분석하기
극단치를 결측 처리했으니 분석하기 전에 결측치를 제거하면 됨. drv(구동 방식)에 따라 hwy(고속도로 연비) 평균이 어떻게 다른지 알아보겠음.
mpg.dropna(subset = 'hwy') \
.groupby('drv') \
.agg(mean_hwy = ('hwy', 'mean'))
{혼자서 해보기} 이상치가 들어 있는 mpg 데이터를 활용해 분석 문제를 해결해 보세요.
우선 mpg 데이터를 불러와 일부러 이상치를 만들겠음. drv(구동 방식) 변수의 값은 4(사륜구동), f(전륜구동), r(후륜구동) 세 종류임. 몇 개의 행에 존재할 수 없는 값 k를 할당하겠음. cty(도시 연비) 변수도 몇 개의 행에 극단적으로 크거나 작은 값을 할당하겠음.
# mpg 데이터 불러오기
mpg = pd.read_csv('mpg.csv')
# drv 이상치 할당
mpg.loc[[9, 13, 57, 92], 'drv'] = 'k'
# cty 이상치 할당
mpg.loc[[28, 42, 128, 202], 'cty'] = [3, 4, 39, 42]구동 방식별로 도시 연비가 어떻게 다른지 알아보려고 함. 분석을 하기 전에 우선 두 변수에 이상치가 있는지 확인하려고 함.
Q1. drv에 이상치가 있는지 확인하고, 이상치를 결측 처리한 다음 이상치가 사라졌는지 확인해보기. 결측 처리를 할 때는 df.isna()를 활용해보자.
mpg.query('drv not in ["4", "f", "r"]')
mpg['drv'] = mpg['drv'].replace('k', np.nan)
mpg['drv'].isna().sum()
# output: 4mpg = mpg.dropna(subset = 'drv')
mpg['drv'].isna().sum()
# output: 0
Q2. 상자 그림을 이용해 cty에 이상치가 있는지 확인하고, 상자 그림 기준으로 정상 범위를 벗어난 값을 결측 처리한 다음 다시 상자 그림을 만들어 이상치가 사라졌는지 확인해보자.
sns.boxplot(data = mpg, y = 'cty')
# 1사분위수의 값
pct25 = mpg['cty'].quantile(.25)
pct25
# output: 14.0# 3사분위수의 값
pct75 = mpg['cty'].quantile(.75)
pct75
# output: 19.0# 1사분위수와 3사분위수의 거리
iqr = pct75 - pct25
iqr
# output: 5.0pct25 - iqr * 1.5 # 하한
# output: 6.5pct75 + iqr * 1.5 # 상한
# output: 26.5따라서 극단치는 6.5 ~ 26.5 범위 밖의 수가 됨.
# 결측치 제거
mpg = mpg.dropna(subset = 'cty')
# 상자 그림 그리기
sns.boxplot(data = mpg, y = 'cty')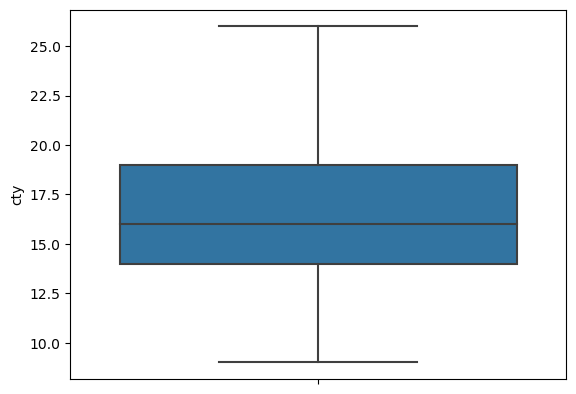
Q3. 두 변수의 이상치를 결측 처리했으니 이제 분석할 차례임. 이상치를 제거한 다음 drv별로 cty 평균이 어떻게 다른지 알아보자. 하나의 pandas 구문으로 만들어야 함.
mpg.dropna(subset = ['drv','cty']) \
.groupby('drv') \
.agg(mean_cty = ('cty', 'mean')) \
.sort_values('mean_cty', ascending = False)
정리하기
## 1. 결측치 정제하기
pd.isna(df).sum() # 결측치 확인
df_nomiss = df.dropna(subset = ['score']) # 결측치 제거
df_nomiss = df.dropna(subset = ['score', 'sex']) # 여러 변수 동시에 결측치 제거
## 2. 이상치 정제하기
# 이상치 확인
df['sex'].value_counts(sort = False)
# 이상치 결측 처리
df['sex'] = np.where(df['sex'] == 3, np.nan, df['sex'])
# 상자 그림으로 극단치 기준 찾기
pct25 = mpg['hwy'].quantile(.25) # 1사분위수
pct75 = mpg['hwy'].quantile(.75) # 3사분위수
iqr = pct75 – pct25 # IQR
pct25 - iqr * 1.5 # 하한
pct75 + iqr * 1.5 # 상한
# 극단치 결측 처리
mpg['hwy'] = np.where((mpg['hwy'] < 4.5) | (mpg['hwy'] > 40.5),
np.nan, mpg['hwy'])
- 7장 END -